Visual speech
recognition
Several experiments were conducted in order to make visual speech
recognition. Images from the M2VTS database were used in order to
make lip location normalization. This study presents a
method which uses visual information from the lips in motion, and is
able to normalize the lip location over all lip images. This method is
based on a search algorithm of the lip position in which a lip location
normalization is integrated in the model training of Hidden Markov
Models, HMMs.
In general terms, this method can be described as the following
iterative procedure:
-
Best Location Search : For a training data set, find the best
lip location data set in the sense that the likelihood of each word
in the data set is the highest for the corresponding HMMs In this
step, for each utterance, an algorithm in order to search around the
current position for the best location is carried out. The lip
location corresponding of an utterance is changed several times and
the likelihood for the corresponding HMMs is calculated. The
lip position with the high likelihood is selected as the best
position.
-
Model Update: Update the HMM models by the Baum Welch
re-estimation algorithm using all training data set having the best
location. In this step, a new set of HMM models is trained,
using the last set of HMM models and using all the utterances with
the best lip position.
All the experiments carried out in this study, use the M2VTS
database, which is based on the image based method with 1850 utterances
and more than 28000 images. The experiments showed that the
proposed method is able to normalize the lip positions effectively and
also show that even a prior normalization method, the proposed one is
able to normalize much more the lip positions.
Figure 1 shows some examples of some images before and after applying
this method.
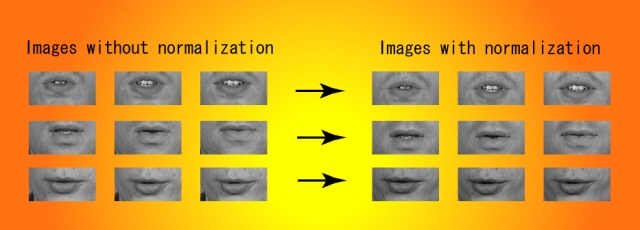
Figure 1. Images before and after
applying the proposed method.
As can be seen, the lip position after applying this method are
centered. Considering that original images presented not centered
lip positions, the visual recognition rates could be improved
notoriously. Figure 2, shows the recognition rates given
after several iterations were applied. A recognition
rate of 67.7% was obtained for "w N" (no normalization was applied),
71.2% was obtained for "w I" (intensity normalization was only applied).
After applying the lip location normalized process, the recognition rate
was increasing up to 76.6% on iteration 3.
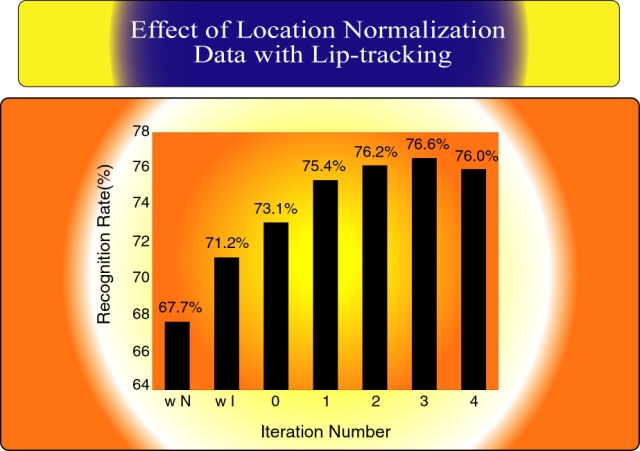
Figure 2. Recognition results given when the
proposed method was applied.
Figure 3 shows the HMMs models before and after this method was
applied. Here we can appreciate that Lip images given by the HMM
models are sharper than those without applying this method.
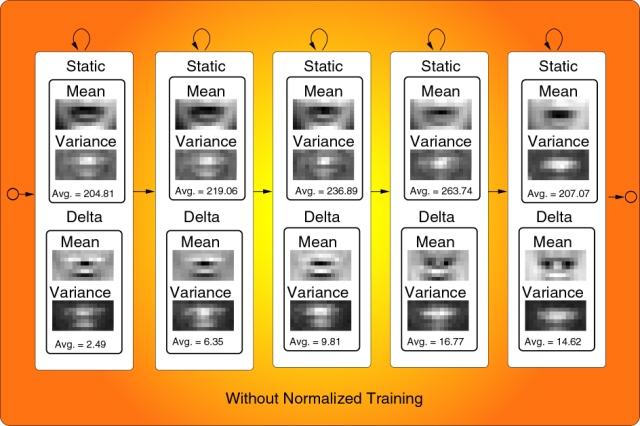
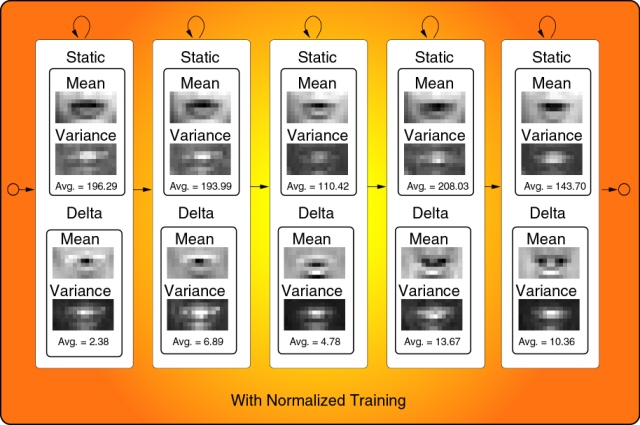
Figure 3. Images given by the HMMs states
before and after the proposed method was applied.
[Home]
This site was last updated
07/06/14
|


